NodeJS
CommonJS 的本质是什么?
CommonJS 是 JavaScript 的模块化规范,它定义了模块的概念,通过模块可以将代码划分为多个逻辑单元,并通过 require() 和 exports 来导入和导出模块。
分析下面代码,使用require()导入这个文件后的结果是什么?
// test.js
this.a = 1;
exports.b = 2;
exports = { c: 3 };
module.exports = {
d: 4,
};
exports.e = 5;
this.f = 6;理解 CommonJS 的本质主要是理解require()函数是如何工作的,它是 node 内部提供的函数,工作原理如下(使用 JS 代码模拟):
- 首先根据传入的模块路径获取模块完整的绝对路径作为模块的 id。
const moduleId = getModuleId(modulePath);2.根据模块 id 判断是否有缓存,如果有缓存,则直接返回缓存的模块对象。
if (moduleCache[moduleId]) {
return moduleCache[moduleId];
}3.如果没有缓存,则运行模块,也就是将模块中的代码放到一个函数中执行。首先需要定义这个执行函数,exports参数初始化为一个空对象,require参数也就是当前这个require函数,module参数初始化为一个对象,它只有一个exports属性,__filename参数初始化为模块的绝对路径,__dirname参数初始化为模块所在的目录。这也就是为什么我们可以在模块中使用这些参(可以在模块中使用arguments对象来查看这些参数)。
function _require(exports, require, module, __filename, __dirname) {
// 用户书写的代码
}4.准备参数并运行执行函数。
const module = {
exports: {},
};
const exports = module.exports;
const __filename = moduleId;
const __dirname = getDirname(__filename);
_require.call(exports, exports, _require, module, __filename, __dirname);5.执行后缓存模块并返回module.exports对象。
moduleCache[moduleId] = module.exports;
reutrn module.exports;从流程和实现上来看,实际上exports、this,module.exports都是引用同一个对象,而导入模块是使用module.exports对象。因此,上文的代码分析结果就显而易见了。
const test = require("./test.js");
console.log(test); // { d:4 }说说 Node 中的Buffer以及应用场景?
在Node.js应用中,需要处理网络协议、数据库操作、接收和处理上传的文件、访问文件系统等,这些操作都需要处理大量的二进制数据,而Buffer就是 Node.js 中一个用于处理二进制数据的对象。它提供了一系列的方法来操作二进制数据,包括创建、写入、读取、剪切、拼接等。
Buffer可以理解成一个数据,数据的每一项都可以保存8位二进制,也就是一个字节。
const buf = Buffer.from("Hello, world!", "utf8"); // 默认编码为 utf8
const buf2 = Buffer.alloc(10, 1); // 创建一个长度为 10 的 Buffer,其中全部填充值为1的字节
console.log(buf); // <Buffer 48 65 6c 6c 6f 2c 20 77 6f 72 6c 64 21>
console.log(buf2); // <Buffer 01 01 01 01 01 01 01 01 01 01>
console.log(buf.toString("utf8")); // Hello, world!为什么会需要Buffer?
正因为流式传输的特性,在接收和处理数据时,如果数据到达的速度比进程消耗的速度快,那么少数早先到达的数据会处于等待区等候被处理;如果数据到达的速度比进程消耗的速度慢,那么早先到达的数据需要在等待区等待一定量的数据到达后才能被处理。这里的等待区就是Buffer(缓冲)。换句话说,Node.js无法控制数据传输的速度和到达时间,它只能决定何时发送数据,这就是为什么需要一个缓存区来调节数据接收和处理的速度。
Buffer的应用场景:
I/O 操作,如文件读写、网络通信等。
加密解密。
zlib.js 压缩解压。
说说 Node 中的Stream及其应用场景?
Stream(流)是一种数据传输的手段,是端到端数据交换的一种方式,它是有顺序的,不像传统的程序那样一次性将内容写入内存,而是逐块读取数据和处理内容,用于顺序读取输入或写入输出。
流可以分为三个部分: 数据源source--> 管道pipe --> 数据目的地dest。基本语法为source.pipe(dest)。
流的种类如下:
Readable 流,用于从数据源读取数据,例如
fs.createWriteStream()。Writable 流,用于向数据目的地写入数据,例如
fs.createReadStream()。Duplex 流(双工流),可读可写流,既可以从数据源读取数据,也可以向数据目的地写入数据。例如
net.Socket。
const { Duplex } = require("stream");
const duplex = new Duplex({
read(size) {},
write(chunk, encoding, callback) {},
});4.Transform 流(双工流),用于在数据读写时对数据进行转换。例如在文件压缩操作时向文件写入压缩数据,并从文件中读取解压数据。
const { Transform } = require("stream");
const transform = new Transform({
transform(chunk, encoding, callback) {},
});应用场景:Stream主要应用场景就是 I/O 操作,如文件读写、网络通信等。
- 响应
GET请求,返回文件数据给客户端。
const server = http.createServer((req, res) => {
const method = req.method;
if (method === "GET") {
const fileName = path.resolve(__dirname, "data.txt");
const stream = fs.createReadStream(fileName);
stream.pipe(res); // 将 res 作为 stream 的 dest
}
});
server.listen(3000);文件操作,如压缩、解压、拷贝等。
构建工具的底层操作,例如
gulp等。
说说Node中的Event Loop(事件循环)以及它和浏览器中的事件循环的区别?
浏览器的事件循环是根据HTML标准实现的,而Node中的事件循环是基于
libuv实现的。libuv是一个C语言实现的高性能解决单线程非阻塞异步 I/O 的开源库,它本质上是对常见操作系统底层异步I/O操作的封装,Node底层就是调用它的API。浏览器中的事件循环和Node中的事件循环都将异步任务划分为宏任务和微任务:
浏览器微任务:
Promise.then()、MutationObserver。浏览器宏任务:
setTimeout/setInterval、 script(整体代码) 、 UI事件 、Postmessage、MessageChannel。NodeJS微任务:
Promise.then、process.nestTick。NodeJS宏任务:
setTimeout、setInterval、setImmediate、script(整体代码)、 I/O 操作。
执行差异:
浏览器中的事件循环:首先脚本本身的执行就是一个宏任务,在执行同步代码时遇到微任务就将它加入微任务队列(FIFO),遇到宏任务就加入宏任务队列(FIFO),当本次脚本的同步代码执行完毕(卡可以看作是一个宏任务结束),就查看微任务队列并依次执行,执行一个微任务就移除微任务队列直到微任务队列执行完毕;接着查看宏任务队列,依次执行。整体执行效果就是一个循环,宏任务->微任务 -> 宏任务。
如果在一轮事件循环中,微任务和宏任务队列都为空,那么主线程会进入idle状态(休眠),此时会保持轮询事件循环,等待响应新的事件(用户输入交互,定时器到期)。
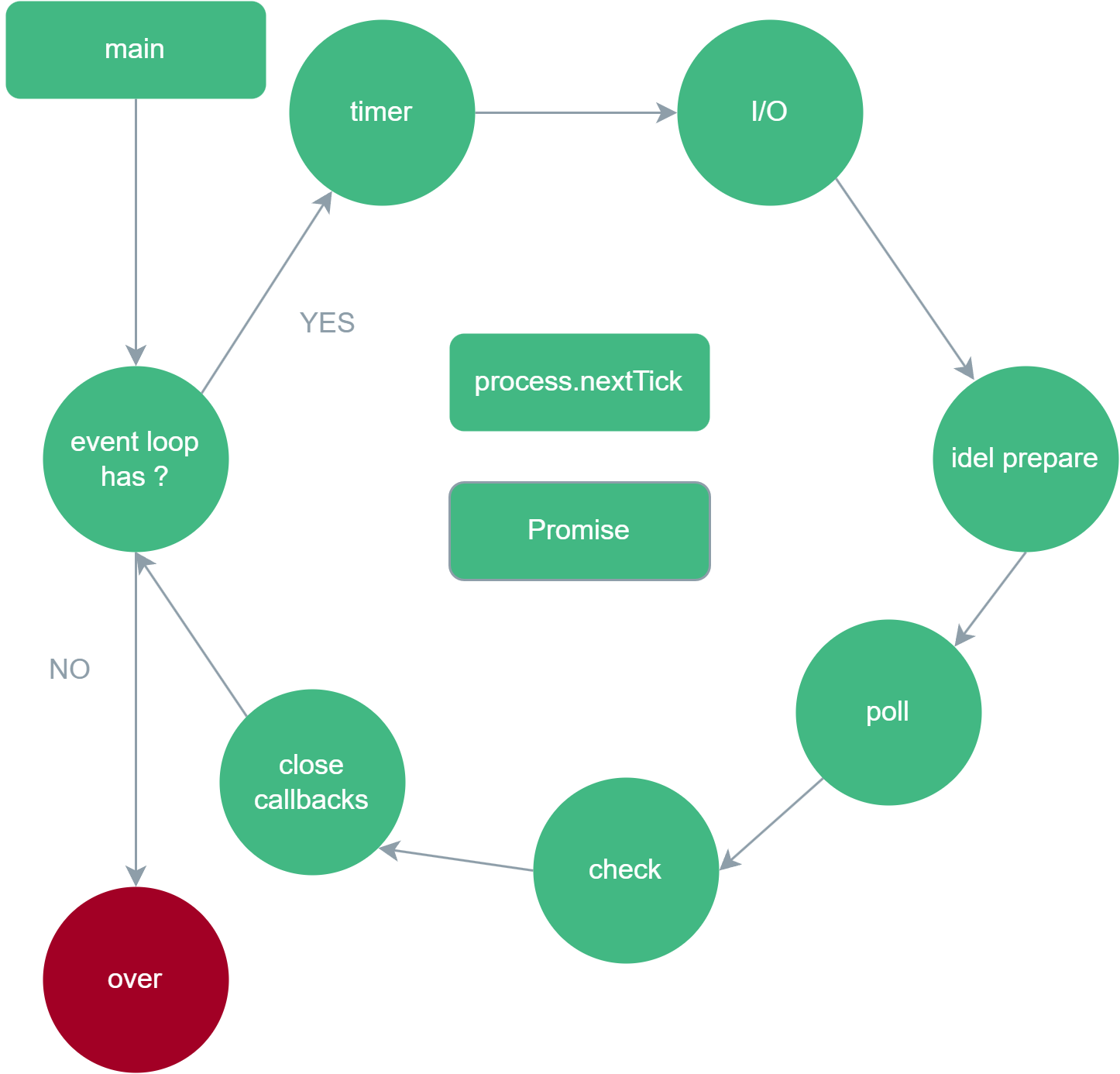
Node中的事件循环:划分为六个阶段,也就是有六个宏任务队列,而微任务队列有两个 process.nextTick 队列和 Promise 队列,它们在进入下一个阶段前必须依次反复清空,直到两个队列完全没有即将到来的任务的时候再进入下一个阶段。process.nextTick 队列的优先级高于 Pormise 队列。
- timer阶段。执行
setTimeout/setInterval的回调,由poll阶段控制。 - I/O callbacks阶段。处理上一轮循环poll阶段中未执行而延迟的I/O回调。
- idle/prepare阶段。仅Node内部使用。
- poll阶段。回到timer阶段执行回调,然后执行I/O回调。在进入poll阶段之前会计算poll阶段的超时时间。如果poll队列有回调任务,依次执行直到队列清空;如果poll队列中没有回调任务,则判断:如果有
setImmediate回调需要执行,poll阶段会结束并进入check阶段;如果没有setImmediate回调需要执行,会等待其他队列的回调被加入到poll队列中并立即执行,等待时间如果超过设定的时间则进入下一次事件循环。如果没有其他队列的回调会被加入poll队列,则结束该阶段,并在本轮事件循环结束后退出node程序。 - check阶段。执行
setImmediate回调。 - close callbacks阶段。执行执行所有注册 close 事件的回调函数。